The point is to assign each rowSum value to each cell in each row, assign each colCum value to each cell in each row.
For example, need to assign 6 to m[0][1], m[1][1], m[2][1].
Check this video for detail process.
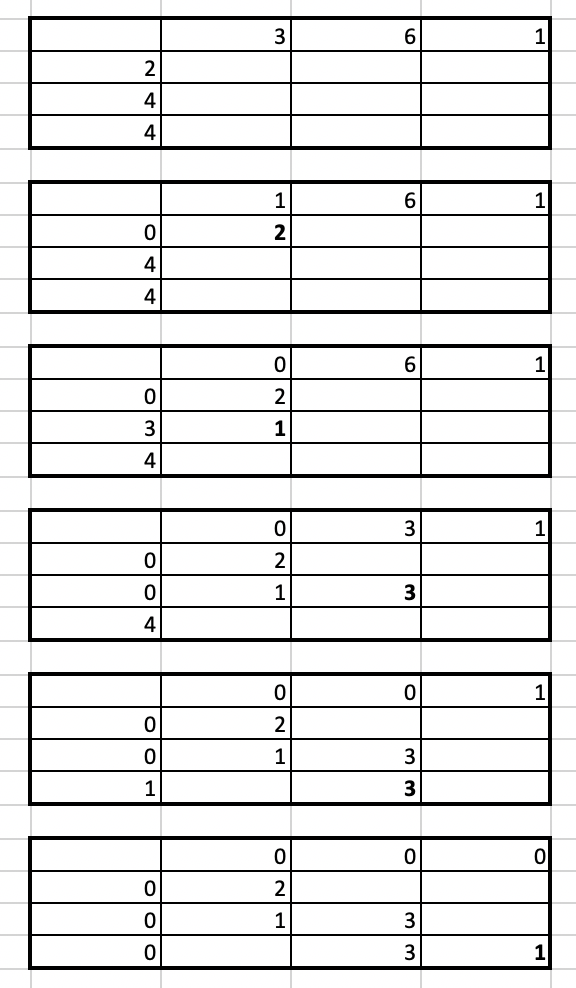
The point is to assign each rowSum value to each cell in each row, assign each colCum value to each cell in each row.
For example, need to assign 6 to m[0][1], m[1][1], m[2][1].
Check this video for detail process.
This is the gray code. The changing rule can be:
rule1: update the rightmost bit
rule2: for xxx100…00, it can change the digit x which is next to 100..00
See lc1611
For example, 1001000 has 2 ways of change:
1. rule1 -> 1001001
2. rule2 -> 1011000
Another example, 1111 has 2 ways of change:
1. rule1 -> 1101
2. rule2 -> 1110
The property of gray code, is that each two adjacent number only have 1 bit difference.
For example, in decimal, if we want to update from 011 to 100, the electronic element may change like 100->101->111->100. There is potential ephemeral number 101, 111. In gray code, this won’t happen. Because each two adjacent number only has 1 bit difference.
| Decimal | Binary | Gray |
|---|---|---|
| 0 | 0000 | 0000 |
| 1 | 0001 | 0001 |
| 2 | 0010 | 0011 |
| 3 | 0011 | 0010 |
| 4 | 0100 | 0110 |
| 5 | 0101 | 0111 |
| 6 | 0110 | 0101 |
| 7 | 0111 | 0100 |
| 8 | 1000 | 1100 |
| 9 | 1001 | 1101 |
| 10 | 1010 | 1111 |
| 11 | 1011 | 1110 |
| 12 | 1100 | 1010 |
| 13 | 1101 | 1011 |
| 14 | 1110 | 1001 |
| 15 | 1111 | 1000 |
Transformation from decimal to gray code. See here.
(10011001)d -> (11010101)gc
Transformation from gray code to decimal. See here
(11010101)gc -> (10011001)d
1. @3:00 Break programs into logically independent components, allowing component dependencies where necessary.
2. @3:10 Inspect your data objects and graph their interactions/where they flow. Keep classes simple. Keep one-way dataflow/interactions simple. @3:29 Simplicity — keep a small number of class types (controller, views, data objects) avoid creating classes that aliases those classes (managers, coordinators, helpers, handlers, providers, executor). @4:02 — Keep dataflow simple (e.g., don’t let Views have business logic; views shouldn’t need to communicate any data upstream).
3. @4:33 Keep data model objects pruned of logic, except if the logic is part of the objects’ states. Single Responsibility Principle. If you can’t describe a class’s responsibility straightforwardly, it’s too complex.
4. @5:25 Inspect class composition (“follow ownership graph”). Follow the life of a child (composed) object to make sure that accessibility to and operations done on that object is managed.
5. @5:55 Singletons (“basically globals floating in a system”). Use dependency injection (?) to ‘scope singletons’ and make them testable (?). Singletons often represent independent (uncoupled) objects which is good for representing independent execution flow. Too many inter-communicating singletons in a system make it difficult to trace data flow and understand the overall transformation of the data through the system.
6. @6:50 Singleton communication patterns. Singletons expose Publisher/Subscriber interface (one publisher object, many subscriber objects listening to events).
7. @7:41 Delegate communication pattern. (?)
8.@8:02 Chain of Responsibility Pattern. Hierarchical data flow — unhandled events bubble upwards to parent objects who should handle them. Conflicts with (2) by allowing upstream dataflow. Use with discretion.
9. @8:53 OOP’s Inheritance can create tightly coupled hierarchical objects that are hard to refactor (object dependencies). Use composition pattern to allow flexibility in what the container object can do.
10. @9:58 Lazy initialization. Startup performance boost.
11. @10:06 Adapter Pattern.
12. @10:26 Factory builder classes.
Manager, Handler, Coordinator, Provider, Executor, Adaptor, Helper
SRP, if a class is doing too much, and can’t tell what is its responsibility. Maybe it’s time for code refactoring and break down to more isolated components.