Today, I tested from scratch to see how to use bean in SpringMVC. The conclusion is that we can either use @Component or xml to define bean.
First, I used Intellij to create a HelloWorld SpringMVC project. Then I added a TestClass bean which I hope to get it from container. The project structure is like below:
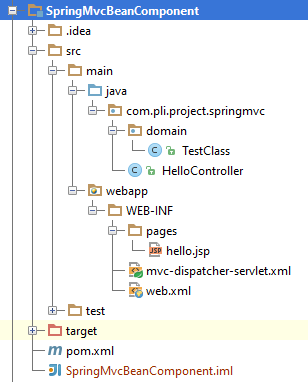
TestClass.java
@Data
@Component
public class TestClass {
private String msg = "bean by component";
}
HelloController.java. We should pay attention to TestClass. It has AutoWired annotation, which means it is injected from bean. So in order to do this, we need to find way to generate TestClass bean. Keep looking below other files.
@Controller
@RequestMapping("/")
public class HelloController {
@Autowired
private TestClass t;
@RequestMapping(method = RequestMethod.GET)
public String printWelcome(ModelMap model) {
model.addAttribute("message", "Hello world!" + t.getMsg());
return "hello";
}
}
hello.jsp
<html>
<body>
<h1>${message}</h1>
</body>
</html>
mvc-dispatcher-servlet.xml. A servlet configuration. It scan all the components in base-package. In this way, the class which annotated with component will be added into container. In this way, the @AutoWired annotated TestClass can be injected.
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="com.pli.project.springmvc"/>
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/WEB-INF/pages/"/>
<property name="suffix" value=".jsp"/>
</bean>
</beans>
web.xml. This is the entry for the servlet. The definition says all url will be forwarded to mvc-dispatcher. In this way, mvc-dispatcher-servlet.xml will be responsible for all requests.
<web-app version="2.4"
xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<display-name>Spring MVC Application</display-name>
<servlet>
<servlet-name>mvc-dispatcher</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>mvc-dispatcher</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
</web-app>
By here, it is done. When we launch jboss and test the webpage, we see below:
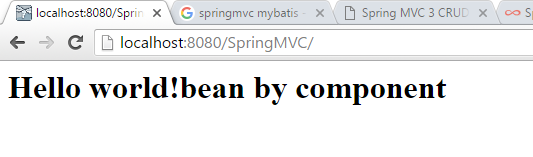
Pay attention to mvc-dispatcher-servlet.xml file. We see that this one is actually a xml file, it defines beans. In this way, we come up another way for beans. We put the bean definition in mvc-dispatcher-servlet.xml file, like below:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="com.pli.project.springmvc"/>
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/WEB-INF/pages/"/>
<property name="suffix" value=".jsp"/>
</bean>
<bean id="testClass" class="com.pli.project.springmvc.domain.TestClass">
<property name="msg" value="Bean by xml" />
</bean>
</beans>
This is more comfortable way which we used a lot in Spring project. Accordingly, I can remove the @Component annotation from TestClass:
@Data
public class TestClass {
private String msg;
}
After we run launch jboss, we see result like below:
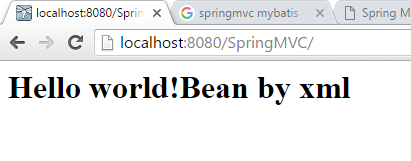
This post summaries 2 ways to define beans in SpringMVC. Hope it helps.
Check my code on github the 2 cases: Bean by component annotation, Bean by Xml