When there are less than 1% non-zero elements in matrix, we call this matrix sparse matrix. Because there are so many 0s in matrix. An efficient way to store sparse matrix is to use three tuple data structure. It stores each non-zero element in matrix. A tuple shows a matrix[i][j]’s value in matrix.
public class Tuple {
int i;
int j;
int value;
}
In this way, data structure for sparse matrix is like:
public class TSMatrix {
public int rowNum; // row length
public int colNum; // column length
public Tuple[] datas;
}
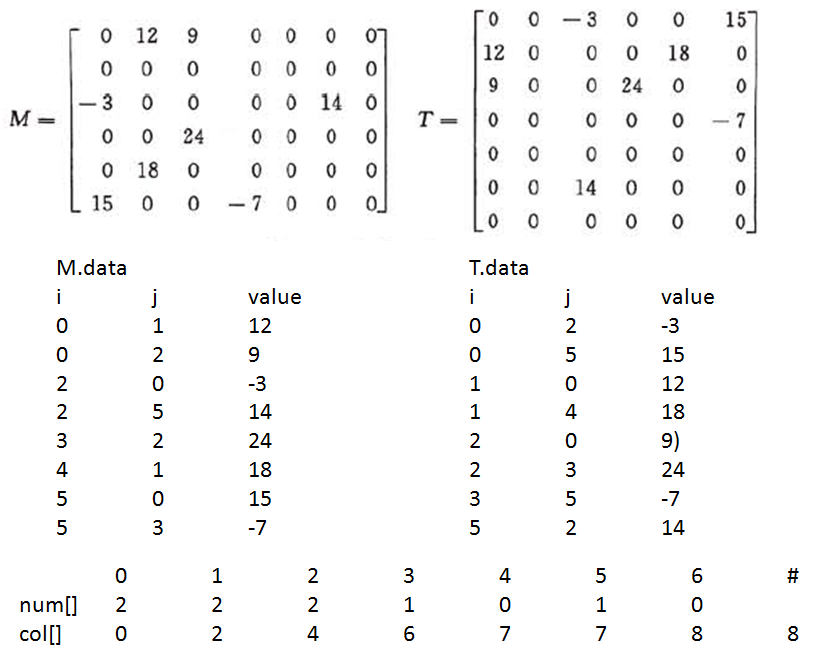
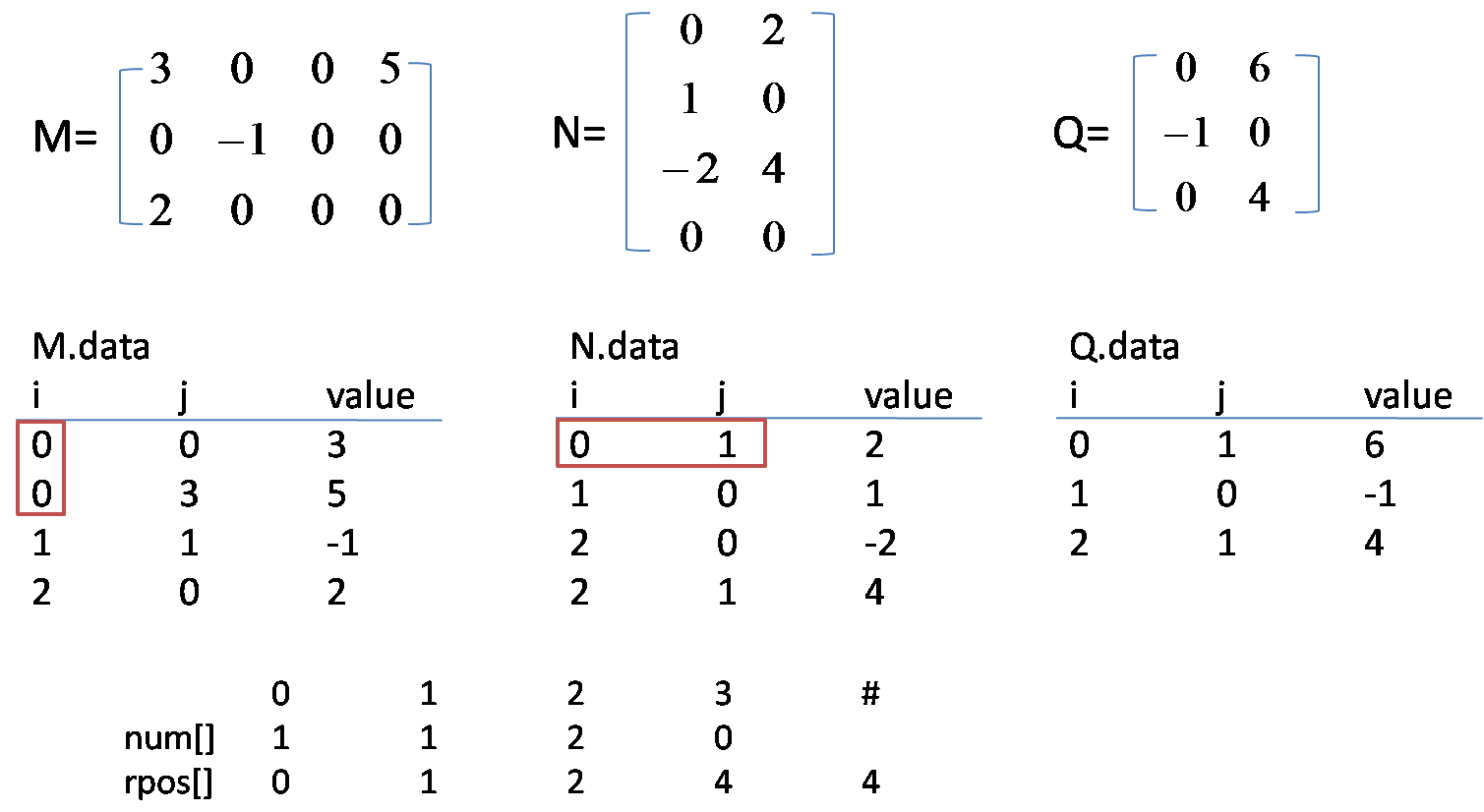
Two classical algorithm for sparse matrix are transpose and multiplication. For transpose, the key is that we should build col. Col[i] tells in new transposed matrix, row[i] start at datas[col[i]]. For multiplication, the key is to build rpos[], rpos[i] means in matrix N row i starts at rpos[i] position in datas[].
Below picture shows process for transpose:
Below shows the process for 2 triple tuple matrix multiplication:
check my code on github: link






